Wiki Devblog - April 14 through April 28
bug fixes (top)
Right after release, there were a handful of pretty harsh bugs to get fixed up!
With the addition of "multiple lyrics", the internal representation for tracks without lyrics was made into an empty array, rather than null. We overlooked this in the "Tracks - with Lyrics" listing, which started displaying every single track!
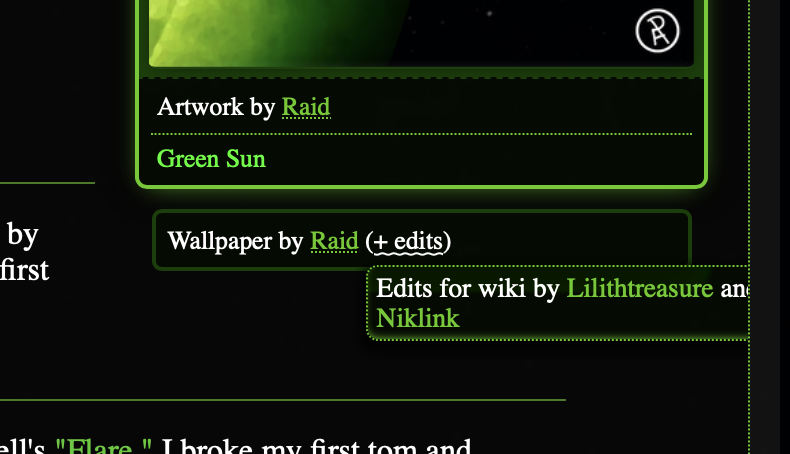
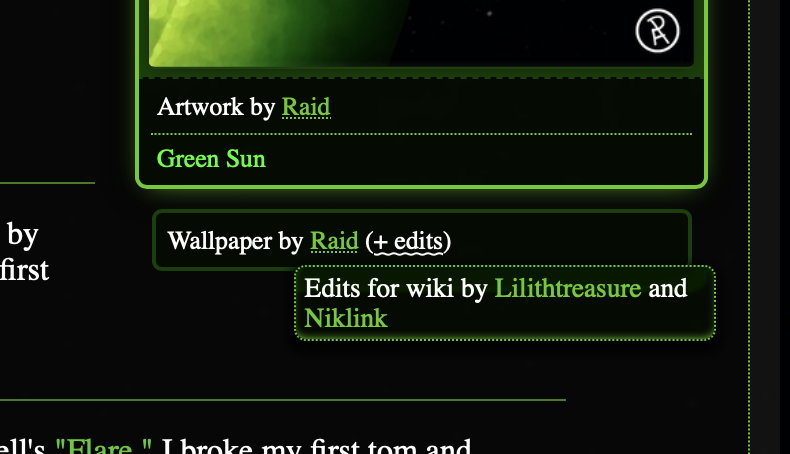
Very strange quirks in the CSS for "wiki edits" tooltips were causing them to escape the page layout, now that this element appears by in the cover art column by the right. We fixed that! That involved tidying some nonsense to do with dynamically positioning this tooltip in particular (because its natural position was out of bounds).
{kind=link}
{kind=link}
We also fixed the cool and new --sort option screwing up Windows line endings. This worked out a lot neater than we worried going in. Line endings still scare us though.
Thanks to Misty for catching the broken lyrics listing, Lilith for spotting out-of-bounds wiki edits, and everyone for keeping cool with --sort.
dated commentary displacement (top)
From their outset, dated commentary entries have posed a trouble. The non-technical gist is that they need to fit, and they're pretty wide... so we just forced them past the cover art column.
This is sort of alright when you've got just one cover artwork. It's less nice when you have two.
{kind=link}
So we tried a new style.
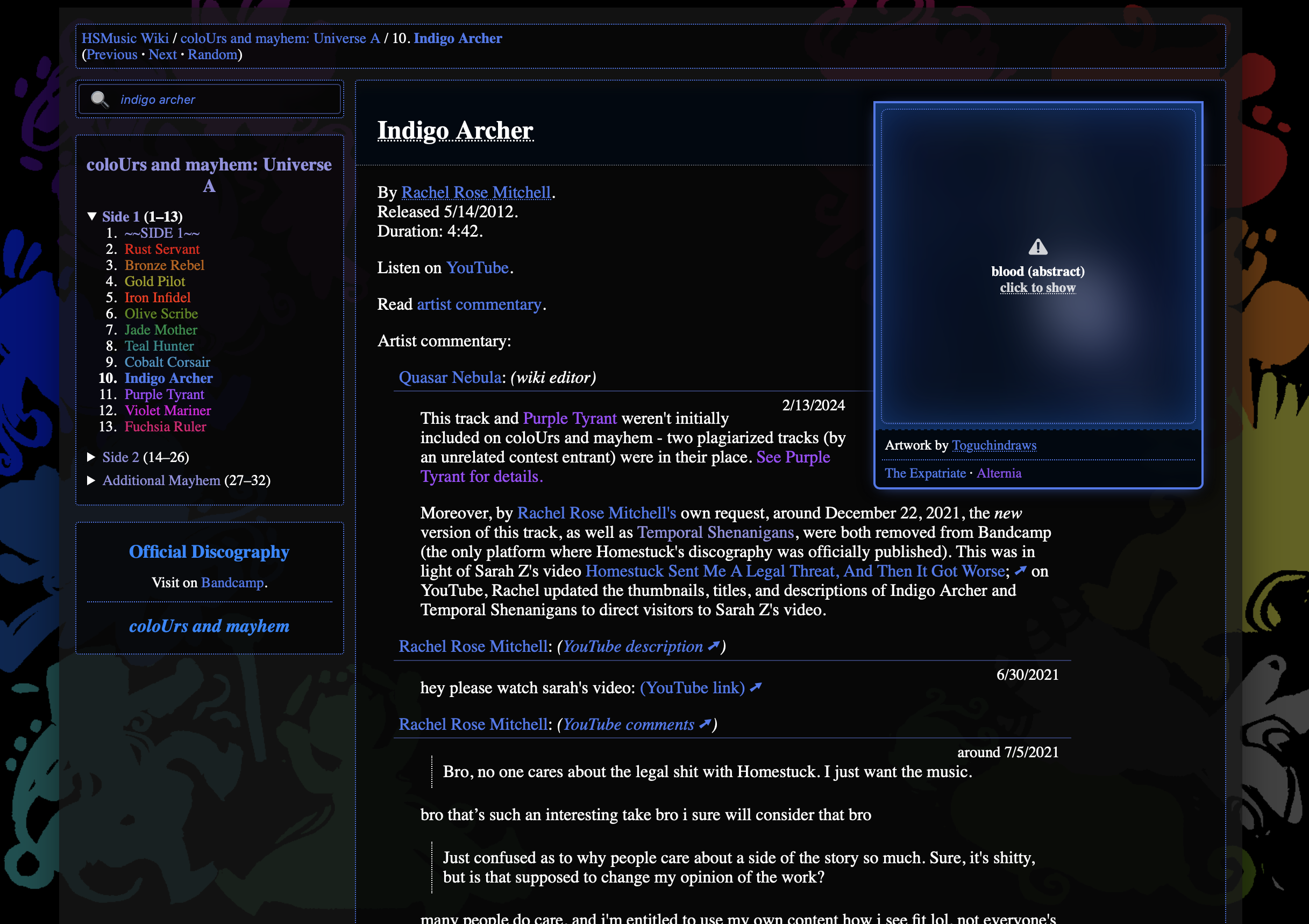
It wasn't all that popular, though. It just feels cluttered!
We ended up going way simpler.
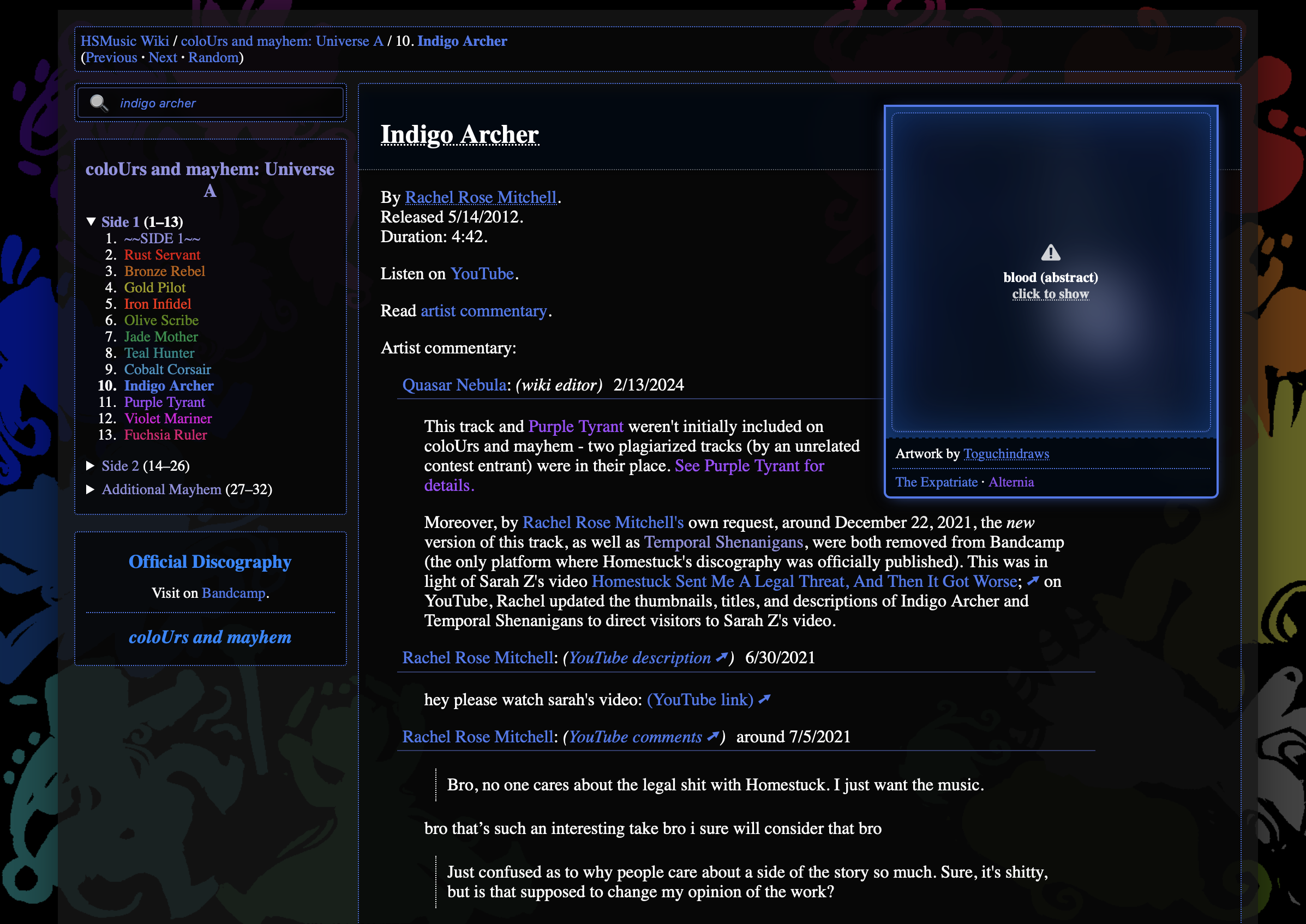
white space (top)
A marked amount of the wiki's design and technical work, in total, go to making sure it's responsive at different screen sizes. We mean really responsive; sure, there are three mildly different "layouts" for thin, medium, and wide displays... but the trick is getting finely differing layouts to look good. This involves lots of terrifying word-wrapping and inline-block and templating-directive science.
But simpler changes are sometimes due, too. Due to an infuriatingly naive technical concession, we instated a max-width: 600px rule for most content elements very early on. Check out the screenshots in "dated commentary displacement" - you're surely used to the layout as it is, and that's thanks to this inconspicuous style.
We got rid of it!
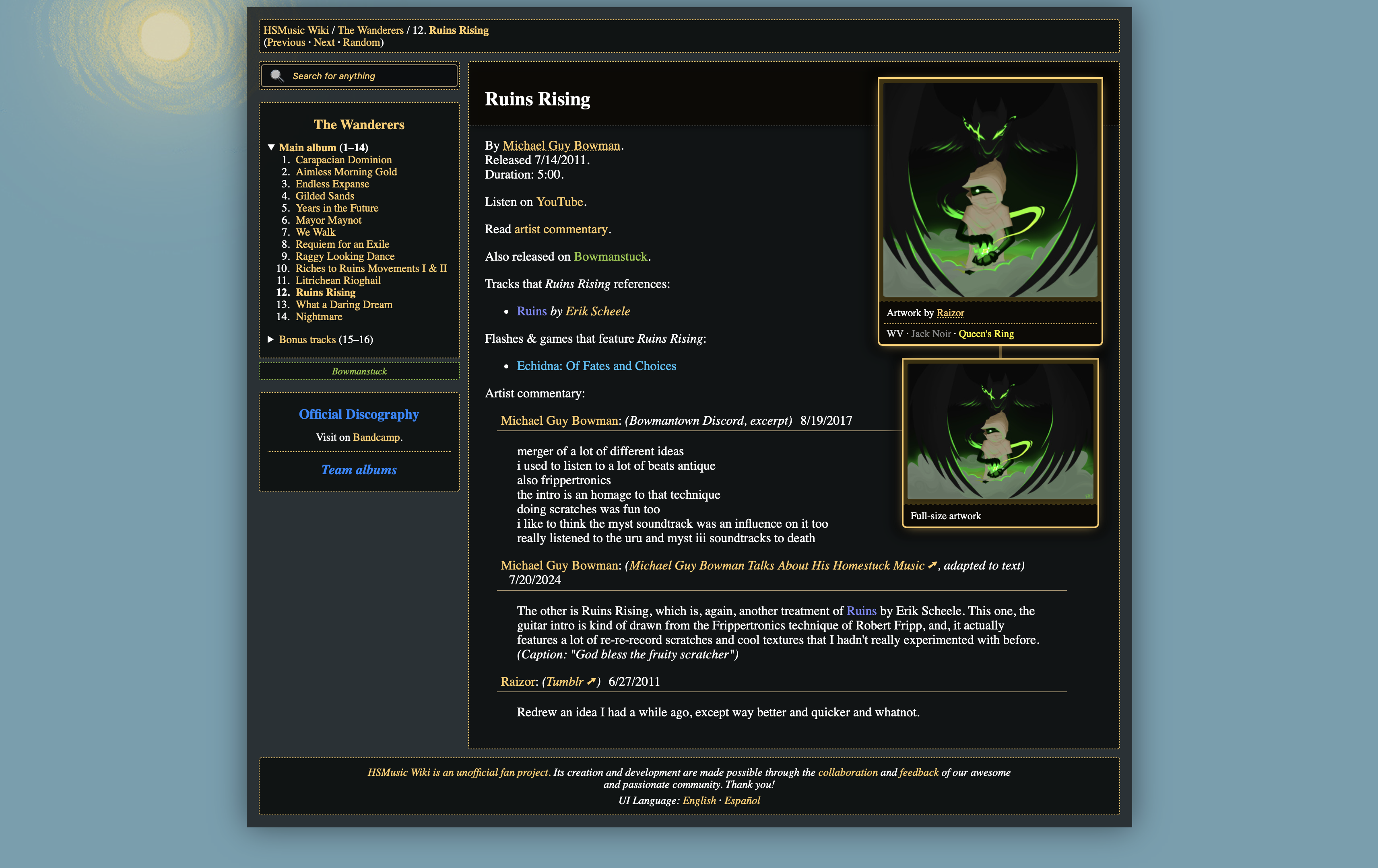
With a keen eye, you might tell we've tweaked the dimensions for cover artworks, too. Not counting the thin layout (which makes cover artworks fill most of the screen), the effective range used to be 200 to 300 pixels; we've tightened that by about 20px on both edges.
The responsiveness math is such that you can comfortably view the art...
- at its largest size, while the sidebar is visible, yet still with a variety of screen widths
- at its smallest size, while the sidebar is visible
- at its largest size, while the sidebar is collapsed
- at its smallest size, while the sidebar is collapsed (but still wider than the "thin" layout)
The crux of all this is hopefully that you - the user! - get a lot more control over the space that stuff on the page really takes up, just by stretching or squishing your browser window. And no matter the dimensions - maybe you're on a tablet or in full screen and don't get to decide - content should take the space that's available a little more gracefully.
artworks attaching above (top)
While porting lots of art about the wiki to the new "multiple artworks" system, we quickly realized that a lot of art... closely accompanies the main artwork... and, consequently, ought to be presented differently than standalone pieces!
Actually, what stood out was that no one really needs the same tag list in their face twice. So we addressed that directly... and then did a similar trick for repeated artist information... and realized this was grounds for a proper feature, really.
So in data, for any artwork, you're now able to specify Attach Above: true. This, well, attaches that artwork to the artwork specified above it.
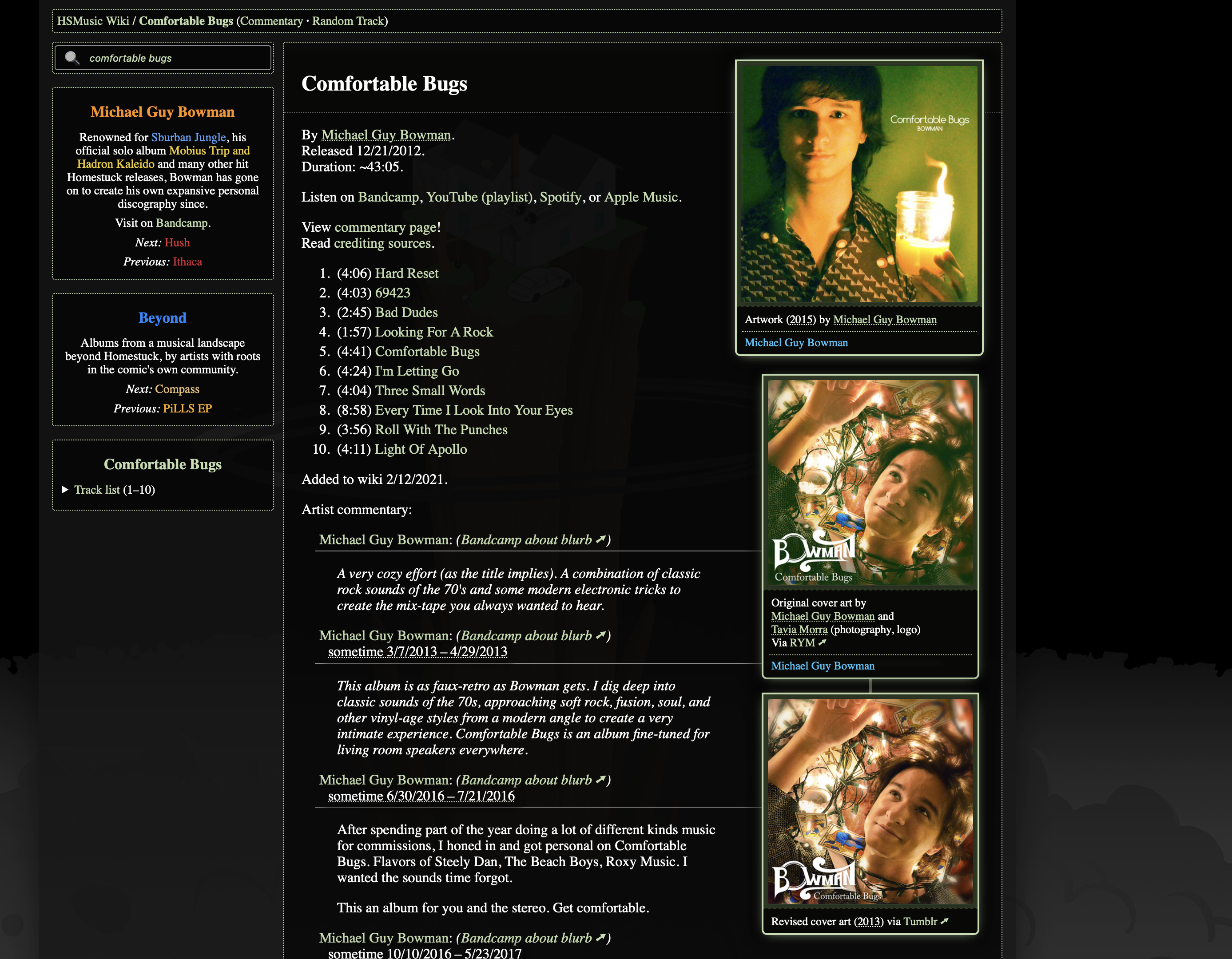
For Comfortable Bugs above, the third artwork has Attach Above: true. This means...
- The third artwork attaches to the second one.
- The third artwork, by default, inherits artist contributions and art tags from the second one.
- The third artwork won't display artist info if it has the same artists (and annotations—all in the same order) as the second one.
- The third artwork won't display tag info if it has the same art tags (in the same order) as the second one.
- The second artwork always displays its full info, because it's not marked
Attach Above: true. It also doesn't inherit any details from any other artwork. - The first artwork doesn't affect any of this, because the third artwork attaches to the second one - not the first!
If there are multiple artworks in a row which have all got Attach Above: true, even though they're displayed as a multiple-link chain, they really all attach to the first-above artwork which isn't marked Attach Above: true. If Comfortable Bugs had a fourth artwork (wow) then it would attach to the second one - meaning it inherits its artists and art tags from the second one, not the third, even though the third is literally right above it.
And that detail matters, because it's perfectly possible for artworks which Attach Above to override those details that are inherited by default! If we spot a secret Stutzman in the background environ of artwork #3 - mysteriously missing from #4 - then his tag will not be inherited onto #4. Likewise, if he really is present in both #3 and #4, he's got to be specified for both.
Attached artworks are a pretty fun feature, but - as of today! - they aren't really integrated outside of info pages, right now. They're really treated just the same as any other secondary artwork. (You could say wiki code opts into being smart with attached artworks... but by default, all the existing code will continue to work - completely ignoring that status.) There's probably plenty room to do more here. As they say - we'll surely see!
search filters (top)
We added a search bar to the wiki back in June 2024. Only it's hardly "back in", because the wiki had been around for four and a half years prior to that point. Regardless, we're going on one year since, and search has changed exactly not at all.
Some spark inspired us that perhaps there ought to be a "search by lyrics" feature on the music wiki - just type up some text into the search box like normal and, if it happens to match any lyrics in the background, those would come up as a little "Lyrics" tab, just alongside the rest of the filter buttons!
Then we realized that those filter buttons still only existed in our head. (Despite having thought at them since before search even released, and having laid out concrete plans back in January this year.) So we got them added!
This one was fun. Sort of like the search bar itself, there isn't a whole lt to say about it. We went for a simpler UI than we imagined at the start - there's no "All" button, the default state is just to to not have a filter active. We hope it's pretty clear that you can, well, clear the filter, by just clicking it again - but we'll mess around with the design some more if that turns out not to be the case.
If you've got a filter active, then it's kept active for your next query too, as long as the results (in total) include some within that filter. Otherwise the filter just gets cleared automatically.
The old style of filtering results, where you just type out the type of thing as part of the query, like rj artist, still works too. It's even integrated nice and fancily here:
Since the typed filter is, well, typed, the only way to disable it is to take it out of your search query. The wiki won't do that for you, so the filter "button" is inert.
search fuzzing (top)
Yep, even more search! We posted the main demo for search filters and everyone loved it, except also (in particular - thanks! - Makin) pointed out that fuzzy search kinda matters more. You know, as far as "gotta do SOMETHING before search goes untouched for an entire year" goes.
Once we'd done a bit of sleuthing around the FlexSearch documentation, we added forward-fuzzy search, which is just about the same as having an asterisk after every word in your search query.
And if that's coming up with the wrong results, just wrap it in quotes!
We hesitate to liken the quotes thing to "verbatim" search, even though that's what it's internally called and obviously we're using quotes and of course it's verbatim search. But it isn't really. We couldn't figure out how to get FlexSearch to care about the order of words. "land fans music of" comes up with exactly the same results.
We're also missing out on some, like... integration... with... the core of how search even works, on the music wiki. It's a whole thing, but the gist is that if your search query happens to include both verbatim and non-verbatim terms, then those are going to run completely separate searches, and the final results will just be whichever are common across both. It's still very fast and will probably find you what you're looking for... as long as you're probably just searching by name, and not meaning to match any other fields.
FlexSearch is indeed very flexible, but if you want to get much of anything done with it, you'll have to get good at flexing it yourself. And we're still learning!
more multiple artworks (top)
In the data department we mostly extended the new "multiple artworks" feature to cover a bunch more artworks scattered about the official discography. We worked at this from two angles:
-
Tidy up the
media/miscfolder, putting the most common categories of remaining standalone art into subfolders. We already had achangelogfolder, for example - now there'santhology-wipsandreferencestoo. Then just trudge through the whole dangmiscfolder, top to bottom, A to Z, searching where each image is used and sticking 'em into "multiple artworks" everywhere applicable. -
Tackle everything from any given album all at once, so stuff from a similar context is tidied up together. We did Homestuck Vol. 7 this way, for example. That was fun!
In particular, courtesy of Meulanie, we had an awesome list of sources for the artwork for Vol. 7 (plus a few pieces from later releases). Vol. 7 in particular collates most of its track artwork from, well, fanart - pieces that might have been making the rounds towards the end of album production, as far as we can tell.
Most of Meulanie's sources were booru pages (web galleries where folk repost others' artworks, mostly for the sake of archival and searchability) - so, not the original sources. However, these booru pages in turn pointed to the actual source URLs. Those were usually from DeviantArt or Tumblr... and long, long gone, too. Trouble in paradise - it's a shame not to preserve and link back where any artwork really was originally posted. But we knew that Tumblr post URLs still work as long as the posts haven't been deleted - if only you can figure out the latest URL for the blog itself. We spent most of an afternoon digging around the artist info we've got (and the Wayback Machine), and were fortunately able to figure out up-to-date sources for lots of those artworks!
As you might surmise - because all this fanart was not made with an album in mind, it usually wasn't square. Even when we couldn't locate the original source, the boorus preserved those original cuts! So we've taken all those and worked them onto the wiki as secondary artworks, providing the best source links we were able to find.
content entries (top)
In YAML data, Commentary fields typically look something like this:
Commentary: |-
<i>Alex Rosetti:</i> (composer, [Tumblr](https://albatrossthesoup.tumblr.com/post/20545830112/my-vol-5-music-commentary), excerpt, 4/5/2012)
I composed this one intending it to be the theme of Jade’s land. This is the reason [[artist:erik-scheele|Jit]] has gone on the record as saying [[track:crystamanthequins|Crystamenthequins]] was intended to accompany Jade’s island being destroyed/her entering her land (I’m pretty sure that’s how he described it) was because of this song. It’s actually a really simple tune [...]
<i>Chumi:</i> (anthology artist, [Tumblr](https://chuchumi.tumblr.com/post/159546207889/heres-my-entry-for-the-volume-5-anthology-i-was), 4/13/2017)
here’s my entry for the [volume 5 anthology](https://vol5anthology.tumblr.com/)! i was lucky enough to be able to draw for [crystalanthemums](https://www.youtube.com/watch?v=j8GVlwRrXC8)! (do yourself a favor and check out everyone else’s AMAZING art and the video pls…)
Content code (broadly - the stuff that turns data into pages!) ends up processing a data structure more like this:
track.commentary: [
{
artists: [ <Artist "Alex Rosetti"> ]
annotation: "composer, [Tumblr](https://albatrossthesoup ..."
date: Date 4/5/2012
body: "I composed this one intending it to be ..."
},
{
artists: [ <Artist "Chumi"> ]
annotation: "anthology artist, [Tumblr](https://chuchumi ..."
date: Date 4/13/2017
body: "here's my entry for the [volume 5 ..."
}
]
This code section is long as fuck. READ ON, IF YOU DARE. :sparkles:
There's quite a slab of processing which turns form A into form B. That processing mainly operates a rather beefy bit of regular expression:
const dateRegex = groupName =>
String.raw`(?<${groupName}>[a-zA-Z]+ [0-9]{1,2}, [0-9]{4,4}|[0-9]{1,2} [^,]*[0-9]{4,4}|[0-9]{1,4}[-/][0-9]{1,4}[-/][0-9]{1,4})`;
const commentaryRegexRaw =
String.raw`^<i>(?<artistReferences>.+?)(?:\|(?<artistDisplayText>.+))?:<\/i>(?: \((?<annotation>(?:.*?(?=,|\)[^)]*$))*?)(?:,? ?(?:(?<dateKind>sometime|throughout|around) )?${dateRegex('date')}(?: ?- ?${dateRegex('secondDate')})?(?: (?<accessKind>captured|accessed) ${dateRegex('accessDate')})?)?\))?`;
This regex defines what a commentary heading looks like. We weren't interested in messing with the wiki's actual data format, so we left it alone, continuing to work with the regex as it was.
However, the regex on its own doesn't take care of everything! Here's some stuff we take care of external to the regex itself:
- Matching artist references, like
"Alex Rosetti", to their actualArtistobjects (we represent this as<Artist "Alex Rosetti">- it means you can do stuff likeentry.artists[0].nameorrelation('linkArtist', entry.artists[0])) - Converting date text into
Dateobjects - Extracting a web.archive.org URL from the annotation, filling in
accessDate(andaccessKind: 'capture') - Getting the body of the entry - the text between each heading, and following the final one!
- Tying everything up into the final object shape
We used to perform all of those steps in one great big "composition", which is the pipeline-style framework which basically all of the wiki's nitty-gritty data processing is written in. It's very cool and powerful and frankly quite simple; but its greatest superpower is, perhaps, giving us all too unwell a feeling when what we're doing is Too Freaking Complicated.
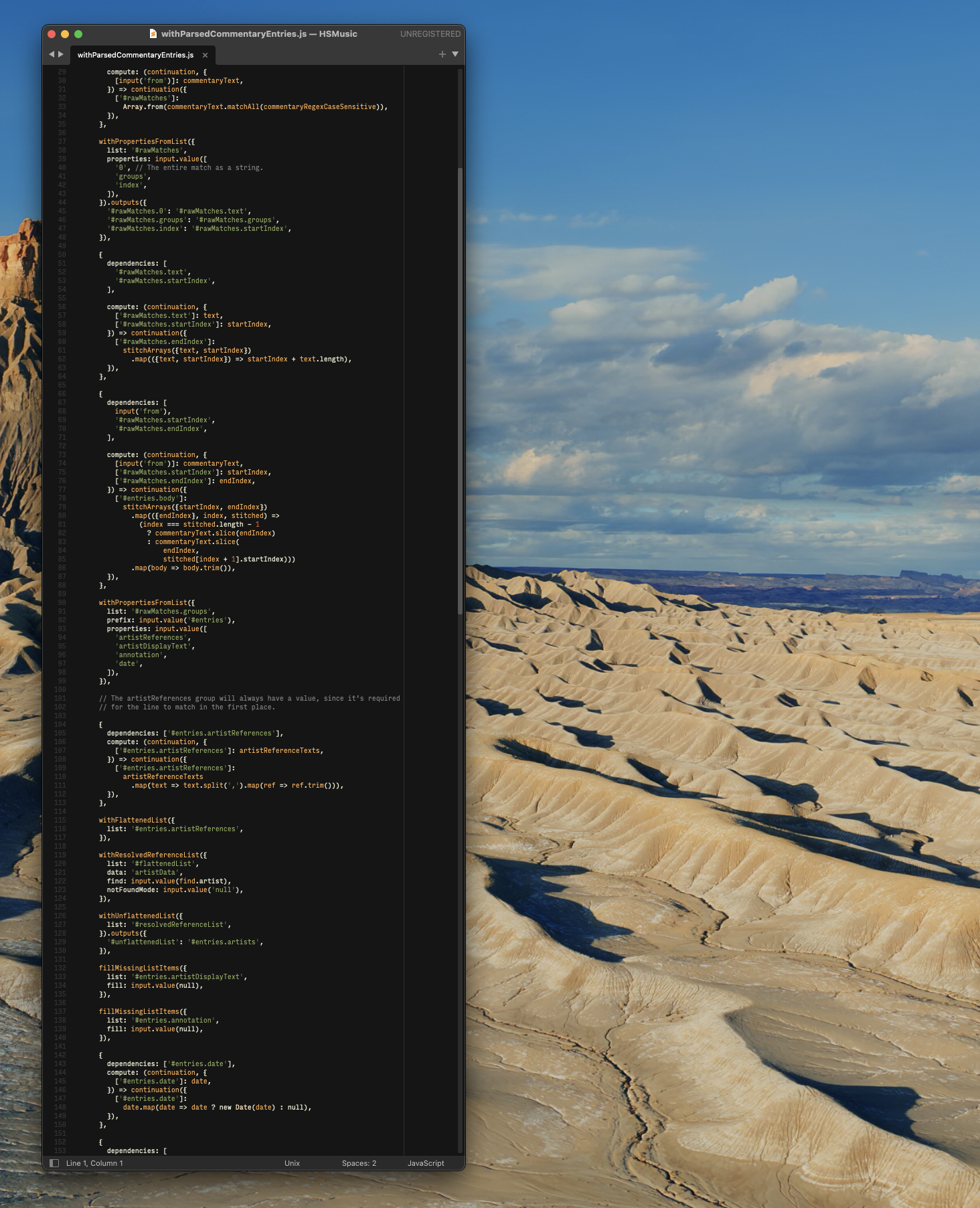
Compositions are basically meant to work with flat lists of values - usually simple values. They can do much more - because you can express just about any wiki data problem in those terms - but it starts to get bulky, quick.
In particular, this composition was responsible for making the entire shape that is expected of content entries (the shape we demoed above). This involves, for example, filling in defaults for each entry.
fillMissingListItems({
list: '#entries.artistDisplayText',
fill: input.value(null),
}),
fillMissingListItems({
list: '#entries.annotation',
fill: input.value(null),
}),
And extracting the list of artist references for each entry.
{
dependencies: ['#entries.artistReferences'],
compute: (continuation, {
['#entries.artistReferences']: artistReferenceTexts,
}) => continuation({
['#entries.artistReferences']:
artistReferenceTexts
.map(text => text.split(',').map(ref => ref.trim())),
}),
},
And matching those references with their actual Artist objects... wait for it... for each entry.
withFlattenedList({
list: '#entries.artistReferences',
}),
withResolvedReferenceList({
list: '#flattenedList',
find: inputSoupyFind.input('artist'),
notFoundMode: input.value('null'),
}),
withUnflattenedList({
list: '#resolvedReferenceList',
}).outputs({
'#unflattenedList': '#entries.artists',
}),
It's all delightfully doable, but boring. And why are we processing... every... single... entry?? During each step of the process?
That's just how compositions work. They're a straight-shot, "A to Z", process everything, now! kind of coding. It's useful for doing lots of closely related tasks in order, where each task clearly builds on previous ones.
And honestly, it works alright for the stuff which runs the regular expression...
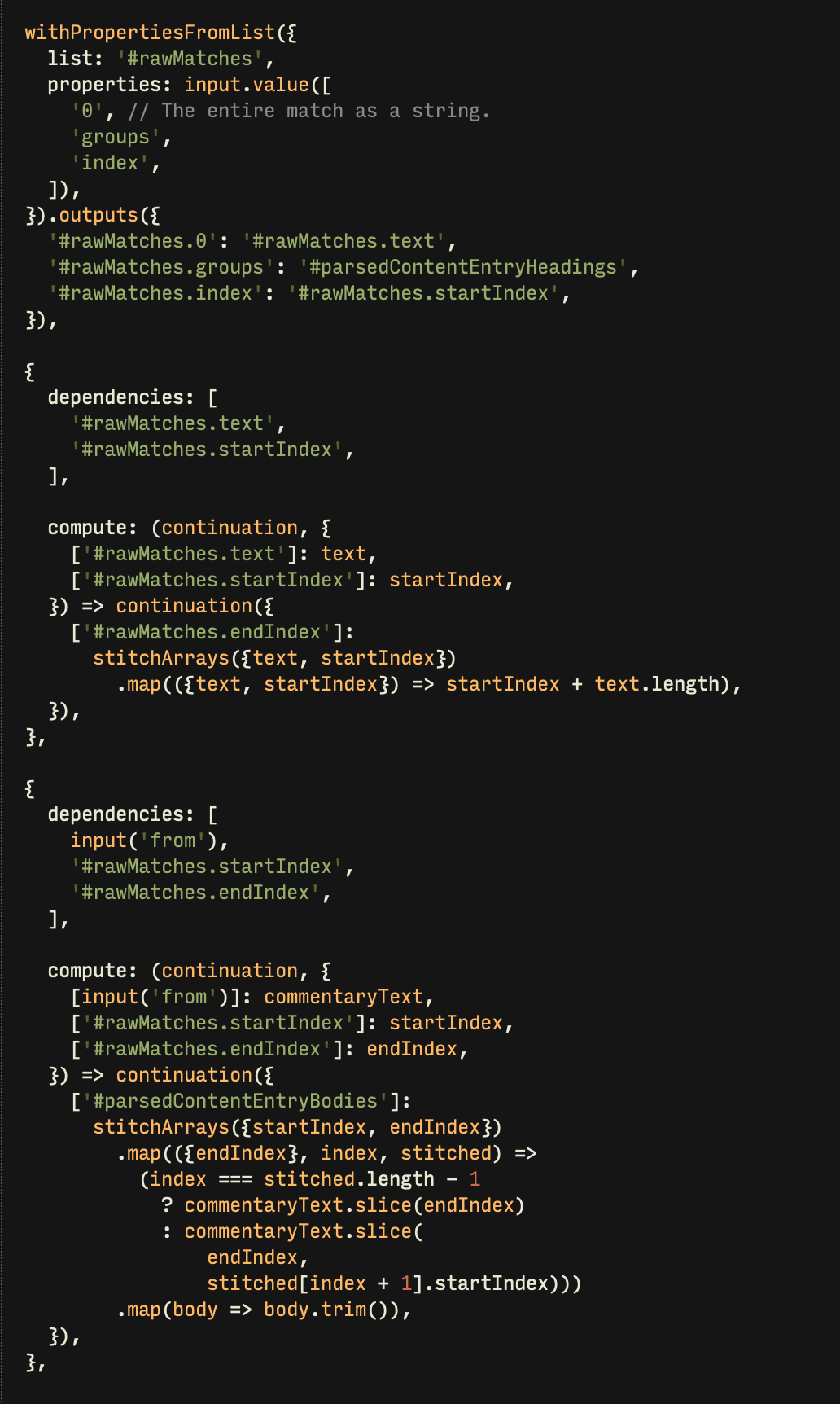
But past the regex, we're handling a bunch of independent tasks. The only reason we even bother with all of them is here and now, well, we've got our input shape, and we're obliged to provide our output shape...
Fortunately we had a minor a-ha moment, very shortly after release. We'd recently worked out a neat and simple way to perform Thing-style processing on the level of sub-things. We figured, hey... the interface we coded for this... would probably just work for commentary entries, right...???
The answer is yeah totally - it did! We swapped the guts of commentary properties (lyrics and crediting sources, too) over the course of an afternoon.
"Thing-style processing" just refers to the framework which makes up all the actual objects - an Album is a thing, so is every Artist and every Track, the likes. (It's kinda OOP-flavored, although that's secondary to just being a useful practice of encapsulation.)
Well, now every ContentEntry is also a thing. And those independent tasks are evaluated... independently!
Defaults are totally free, because on Thing objects, every property either has a value (as specified) or is null.
static [Thing.getPropertyDescriptors] = ({Artist}) => ({
...
artistText: contentString(),
annotation: contentString(),
...
});
And matching references is trivial. That's a first-class operation because it represents like 90% of what the music wiki does LOL:
...
artists: referenceList({
class: input.value(Artist),
find: soupyFind.input('artist'),
}),
...
Alright, but how about parsing those references? You know, the text.split(',').map(ref => ref.trim()) part? And what about the regular expression? How are we getting these ContentEntry objects?
The guts are a dead-normal JavaScript function.
export function matchContentEntries(sourceText) {
const matchEntries = [];
let previousMatchEntry = null;
let previousEndIndex = null;
for (const {0: matchText, index: startIndex, groups: matchEntry}
of sourceText.matchAll(commentaryRegexCaseSensitive)) {
if (previousMatchEntry) {
previousMatchEntry.body = sourceText.slice(previousEndIndex, startIndex);
}
matchEntries.push(matchEntry);
previousMatchEntry = matchEntry;
previousEndIndex = startIndex + matchText.length;
}
if (previousMatchEntry) {
previousMatchEntry.body = sourceText.slice(previousEndIndex);
}
return matchEntries;
}
In fact, this doesn't even "process" the regular expression so much as just run it. The final output, per entry, is literally the groups from the raw matches, plus a body property filled in with the relevant text.
The boilerplate is a bit more interesting, but let's look at that from the top down.
static [Thing.yamlDocumentSpec] = {
fields: {
...
'Commentary': {
property: 'commentary',
transform: parseCommentary,
},
...
},
};
Just a normal transform function, for converting some raw YAML value into a JavaScript-lookin' shape. So what's going on in parseCommentary?
export function parseCommentary(sourceText, {subdoc, CommentaryEntry}) {
return parseContentEntries(CommentaryEntry, sourceText, {subdoc});
}
export function parseCreditingSources(sourceText, {subdoc, CreditingSourcesEntry}) {
return parseContentEntries(CreditingSourcesEntry, sourceText, {subdoc});
}
export function parseLyrics(sourceText, {subdoc, LyricsEntry}) {
if (!multipleLyricsDetectionRegex.test(sourceText)) {
const document = {'Body': sourceText};
return [subdoc(LyricsEntry, document, {bindInto: 'thing'})];
}
return parseContentEntries(LyricsEntry, sourceText, {subdoc});
}
parseCommentary is one of several wrapper functions. They're mostly a handy shorthand, though parseLyrics has a little more going on (the wiki optionally supports multiple "lyrics entries" per track).
parseContentEntries is the real point of conversion, from regex groups to ContentEntry documents. And - look! There's the code that splits the artist reference lists!
export function parseContentEntries(thingClass, sourceText, {subdoc}) {
const map = matchEntry => ({
'Artists':
matchEntry.artistReferences
.split(',')
.map(ref => ref.trim()),
'Artist Text':
matchEntry.artistDisplayText,
'Annotation':
matchEntry.annotation,
'Date':
matchEntry.date,
'Second Date':
matchEntry.secondDate,
'Date Kind':
matchEntry.dateKind,
'Access Date':
matchEntry.accessDate,
'Access Kind':
matchEntry.accessKind,
'Body':
matchEntry.body,
});
const documents =
matchContentEntries(sourceText)
.map(matchEntry =>
withEntries(
map(matchEntry),
entries => entries
.filter(([key, value]) =>
value !== undefined &&
value !== null)));
/* editor's note: we literally just weren't
* sure whether unmatched regex groups have
* the value `undefined` or `null` LOL
*/
const subdocs =
documents.map(document =>
subdoc(thingClass, document, {bindInto: 'thing'}));
return subdocs;
}
The magic here is in subdoc. That's the "sub-things" feature we were referring to earlier, which we figured out for multiple artworks. And it's so simple to use: just give it something that looks like an ordinary YAML document, and it'll turn that into a bona fide Thing instance, prepared just the same as any top-level real YAML document! (yes subdocs can include subdocs lol)
The transformation function, parseContentEntries, amounts to the real YAML we specified earlier amounting to just this:
Commentary:
- Artists:
- Alex Rosetti
Annotation: >-
composer, [Tumblr](https://albatrossthesoup.tumblr.com/post/20545830112/my-vol-5-music-commentary), excerpt
Date: 4/5/2012 # This is still a string!
Body: |-
I composed this one intending it to be the theme of Jade’s land. This is the reason [[artist:erik-scheele|Jit]] has gone on the record as saying [[track:crystamanthequins|Crystamenthequins]] was intended to accompany Jade’s island being destroyed/her entering her land (I’m pretty sure that’s how he described it) was because of this song. It’s actually a really simple tune [...]
- Artists:
- Chumi
Annotation: >-
anthology artist, [Tumblr](https://chuchumi.tumblr.com/post/159546207889/heres-my-entry-for-the-volume-5-anthology-i-was)
Date: 4/13/2017
Body: |-
here’s my entry for the [volume 5 anthology](https://vol5anthology.tumblr.com/)! i was lucky enough to be able to draw for [crystalanthemums](https://www.youtube.com/watch?v=j8GVlwRrXC8)! (do yourself a favor and check out everyone else’s AMAZING art and the video pls…)
That is a little bit junk to write in real data files. transform: parseCommentary lets us stick with the format we're used to; it's just a little boilerplate that gives us access to all the benefits of standalone ContentEntry things!
☕️ (top)
Over the last handful of months, we've done a bunch of our really focused wiki work... at a coffee shop!! They are super nice and never kick us out, very cool and sweet on their part. We buy our keep with like one coffee every two and a half hours and it is lovely.
We also realized that like, it would not be the END of the world if we gave people a way to ✨support our work✨. So we did! We've got a Ko-fi now! ko-fi.com/qzneb wowwwww
Hosting the wiki is pretty cheap and never something we're gonna hold over the head of "donations please", so ko-fi tips DO NOT cover server or domain costs, not one bit. We're still happily handling those out of pocket. Ko-fi tips buy us coffee. Yum yum yum you can now caffeinate us for free for money. Thank you very much!
COFFEE COUNT: LIKE SEVEN OR SO
YOU (yes you) TIPPED US: three of them I think :) thank you
If you're reading this when it's supposed to be linked, hopefully all the stuff we've gone over here is live on the preview website!! Including our multiple artworks data stuff, even though that's not merged into the official preview branch yet. Check it out check it out, offer feedback in Discord or over email, and see you in probably two weeks!!
https://preview.hsmusic.wiki
https://ko-fi.com/qzneb
slurp
~ QN